


产品中心PRDUCTS
技术支持RECRUITMENT
江南体育app北大彭练矛院士、张志勇教授团队再发Nature Electronics!
2024-07-23 21:21:01
江南app数据密集型计算任务的增长需要具有更高性能和能效的处理单元,但使用传统半导体技术越来越难以实现这些要求。 一种潜在的解决方案是将设备的开发与系统架构的创新结合起来。
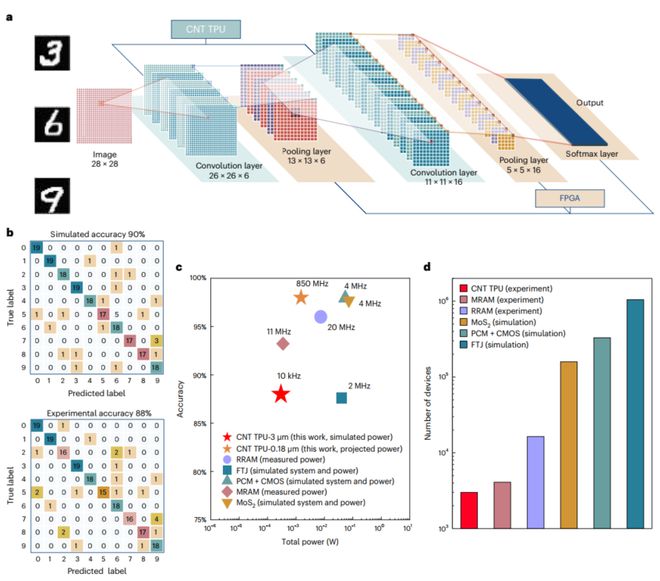
在此,北大彭练矛院士、张志勇教授报告了一种基于3000个碳纳米管场效应晶体管的张量处理单元(TPU),可以执行节能的卷积运算和矩阵乘法。TPU采用脉动阵列架构构建,允许并行2位整数乘法累加运算。基于TPU的五层卷积神经网络可以在295μW的功耗下执行MNIST图像识别,准确率高达88%。他们使用优化的纳米管制造工艺,提供99.9999%的半导体纯度和超洁净表面,从而使晶体管具有高导通电流密度和均匀性。通过系统级模拟,作者估计采用180 nm技术节点的纳米管晶体管制成的8位TPU可达到850 MHz的主频率和每秒每瓦1万亿次操作的能效。相关研究成果以题为“A carbon-nanotube-based tensor processing unit”发表在最新一期《Nature Electronics》。

北京大学信息科学技术学院电子学系主任、中国科学院院士彭练矛曾经在北京碳基集成电路研究院接受澎湃新闻专访时说道:“我们在碳基集成电路这条路上走了20年,还没有看到什么令我们觉得走不下去的障碍。”
我国从2000年就开始了针对碳基电子学的研究工作。2007年,北京大学彭练矛院士、张志勇教授团队就提出了非掺杂制备碳纳米管CMOS器件的方法,制备出了第一个性能超过同尺寸硅基晶体管的碳纳米管晶体管器件。2017年,团队在Science上发文,首次制备了5 nm技术节点的顶栅碳纳米管场效应晶体管,器件的本征性能和功耗综合指标上性能相较同尺寸的传统硅基晶体管器件约有10倍的优势,展现了碳纳米管电子学的巨大潜力。

2020年5月份,该团队再次在Science发文,采用多次提纯和限域自组装的方法,在四英寸基底上制备了高密度江南体育app,纯度超过99.9999%的碳纳米管平行阵列,达到了超大规模碳纳米管集成电路的需求,为推进碳基集成电路的实用化和工业化奠定了基础。

CNT TPU由3x3处理元件(PE)阵列、控制模块和输入/输出多路复用器组成。每个PE均设计为执行2位整数乘法累加(MAC)运算。整个TPU由大约3000个CNT FET 构成。制造工艺包括几个创新步骤,以确保CNT晶体管的高性能,例如:(1)高纯度碳纳米管薄膜:通过多重分散分选方法实现。(2)超洁净表面:通过结合退火和湿法清洁工艺来确保。
图1描绘了CNT TPU的整体系统架构,显示了PE、控制模块和多路复用器的排列。它包括所制造的CNTFET的SEM图像及其结构图,强调了CNT网络的高均匀性和纯度。
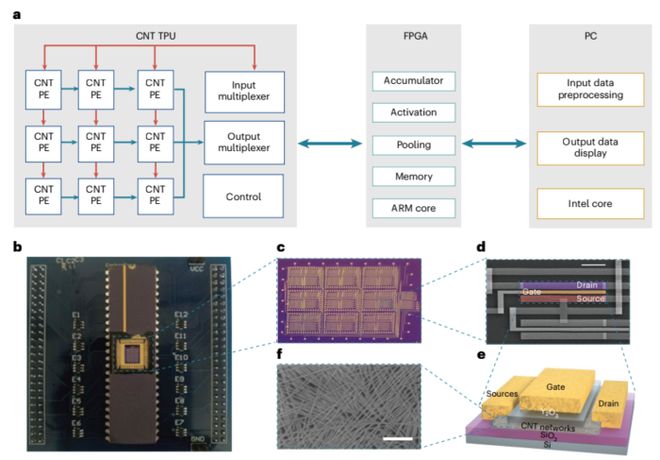
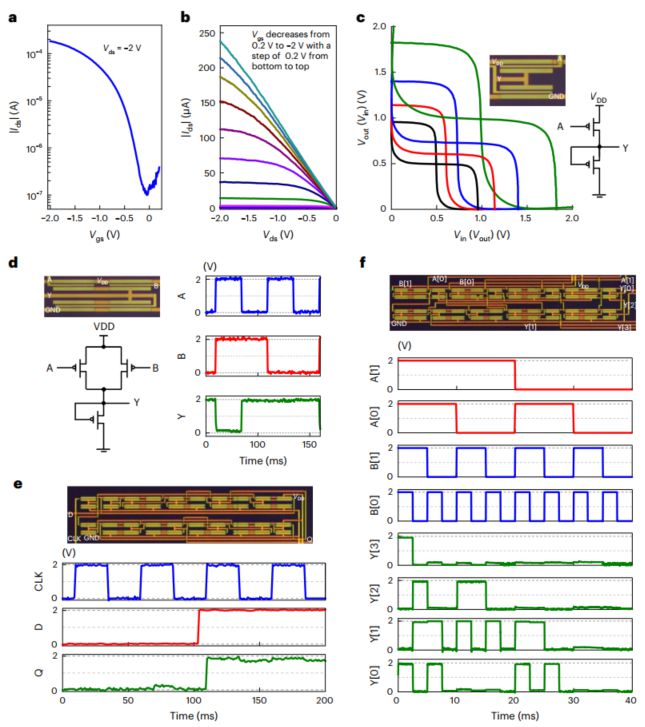
图2显示了CNTFET的电气特性,包括传输和输出特性,以及反相器和NAND门等基本逻辑门的性能。它强调了基于CNT的逻辑门的稳健性和高性能。
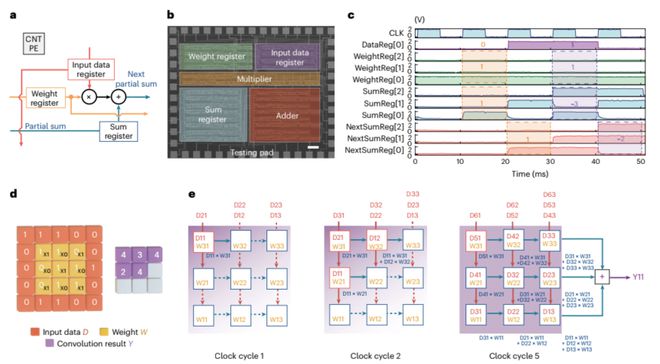
脉动阵列架构是CNT TPU的关键要素。它涉及以规则阵列组织简单的PE,从而降低设计复杂性并增强容错能力。每个PE执行MAC操作并将结果传递到网状拓扑中的相邻PE,从而实现高效的数据流并降低能耗。这种架构对于神经网络中的卷积运算非常有效,其中数据和权重通过数组传播,执行部分求和并按顺序生成最终输出。图3显示了脉动阵列中PE的内部结构,包括乘法器、加法器和寄存器等组件。它还通过详细的SEM图像和测试信号演示了卷积运算期间的数据流。
为了展示CNTTPU的功能,研究人员实施了图像边缘提取和手写数字识别任务。TPU以令人印象深刻的精度和低功耗执行这些任务:(1)图像边缘提取:使用3x3内核捕获图像轮廓。应用多个内核来改善细节捕获,展示了TPU执行复杂图像处理任务的能力。(2)手写识别:构建了五层卷积神经网络(CNN),在识别MNIST数据集中的手写数字时实现了88%的准确率,而功耗仅为295µW。图4展示了使用不同内核的图像边缘提取的结果。它比较了单个内核和组合内核捕获的轮廓,展示了TPU提取详细边缘信息的能力。

图 5详细介绍了使用CNT TPU 实现的五层 CNN 的架构和性能。它包括与其他硬件系统的功耗和准确性的比较,强调了TPU在手写识别任务中的效率和准确性。
矩阵乘法是CNT TPU的另一个重要应用。脉动阵列架构通过充分利用输入数据并最大限度地减少数据移动,提供了优于传统并行矩阵乘法器的固有优势。这可以加快计算速度并降低能耗,使CNT TPU对于大规模矩阵运算非常高效。图6比较CNT TPU和传统并行矩阵乘法器在矩阵乘法任务期间的数据流和能耗。它凸显了CNT TPU对于大规模矩阵运算的卓越能源效率和速度。
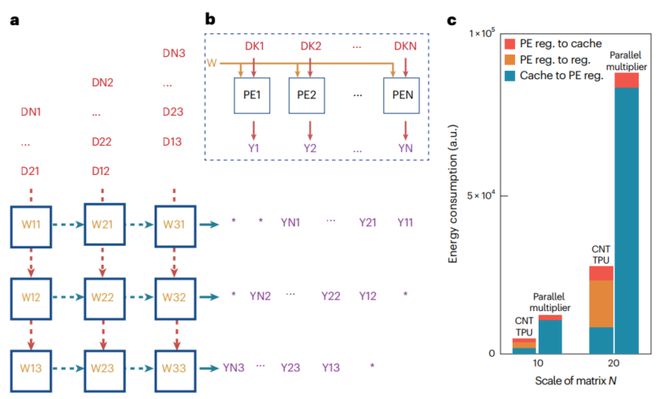
CNT TPU代表了张量处理单元领域的重大进步,集高能效、可扩展性和稳健性能于一身。通过利用CNT的独特属性和脉动阵列架构,该TPU非常适合各种数据密集型应用,从图像处理到神经网络计算。创新的制造工艺确保了CNT的高纯度和均匀性,为未来超越硅计算技术的发展铺平了道路。